(RA3) Single-Zone Multi-Server Architecture Explained
The RA3 architecture is the point in the Kasm deployment progression where the platform's design philosophy is fully expressed in a single-region topology. This completes the role separation that RA2 begins and adds the redundancy mechanisms that transform each separated role from a potential single point of failure into a resilient, independently managed tier.
RA3 is the architecture most production enterprise deployments should be running. It is also the foundation that RA4 extends without fundamentally changing. Everything RA4 does is add geographic distribution of the session plane on top of an RA3 control plane. Understanding RA3 means understanding not just the component topology, but the reasoning that produced each architectural decision within it.
Reference Architecture 3
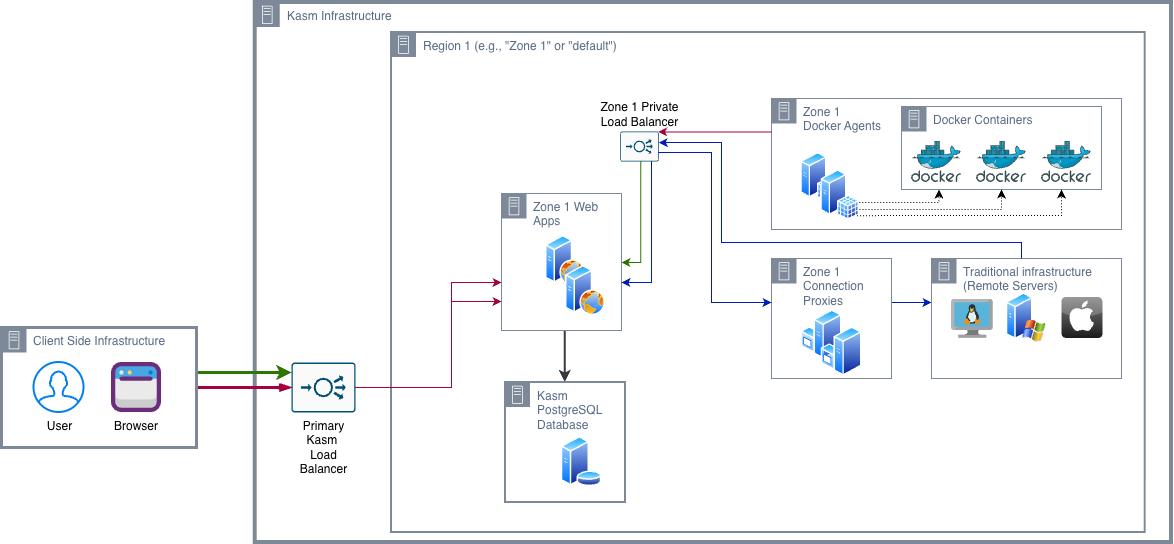
The Primary Load Balancer
Each Kasm Web App role includes an NGINX container kasm_proxy that serves as a required front-end to internal services. While this component is integral to system operation, organizations may enhance their security posture by either hardening this configuration or deploying Kasm Workspaces behind an enterprise-grade reverse proxy or load balancer.
Enterprise security solutions can provide advanced protections such as Web Application Firewall (WAF) capabilities, DDoS mitigation, and Zero Trust access controls. Additionally, SSL/TLS offloading can centralize traffic management and reduce processing overhead on backend Kasm services, improving both performance and resource efficiency.
All user interactions, authentication, session initiation, and workspace streaming enter the environment through a single public endpoint, the Primary Load Balancer. This abstraction presents the deployment as a unified service, regardless of the underlying multi-node architecture.
A critical requirement of the Primary Load Balancer is continuous backend health awareness. The Kasm Web App exposes a /api/__healthcheck endpoint that verifies both application availability and database connectivity. If a Web App instance becomes unable to reach the database, it is automatically marked unhealthy and removed from traffic routing.
For production deployments, a network load balancer is the recommended approach. Unlike DNS round-robin, which relies on TTL expiration and may continue routing traffic to failed nodes for 90–300 seconds, a network load balancer performs active health checks and reroutes traffic to healthy instances within seconds, ensuring higher availability and a more reliable user experience.
Private Load Balancer
One of the subtler architectural decisions is the use of a private load balancer within each zone. The private load balancer is positioned between the Web App nodes on one side, and the Agent and Connection Proxy nodes on the other.
This design establishes an internal routing path for control-plane traffic, ensuring it remains within the private network. As a result, control traffic does not traverse the external load balancer interface, improving both efficiency and security.
The Web App Tier: Statelessness as an Architectural Superpower
The Web App tier is the control plane of the RA3 deployment. Multiple Web App servers run behind the Primary Load Balancer, forming an HA cluster that makes the control plane resilient.
The property that makes horizontal scaling of the Web App tier straightforward is statelessness. No session state lives inside the Web App process. Everything is delegated to the database. Any Web App instance can be removed from the cluster at any time without affecting users interacting with other instances. A Web App server that needs patching is drained from the load balancer, patched and rebooted, and returned to the cluster with no user-facing interruption.
The recommended minimum for production RA3 Web App high availability is N+1: one more Web App server than needed to serve peak load. An organization expecting 500 concurrent users might require 2 Web App servers at peak. N+1 means deploying 3, providing both failure tolerance and maintenance flexibility simultaneously. Every instance is active and capable of serving any request. There is no primary or secondary designation, no active-passive relationship.
Database
The database sits in a dedicated segment, isolated awar from the internet-facing infrastructure boundary. This placement reflects the database's distinct security requirements and its role as the only stateful component in the entire deployment.
When the database is unavailable, the entire platform is operationally blocked. No component in the Web App tier can perform its core function without database access. This is the single most consequential availability dependency in the entire deployment, and it is the one that most frequently receives insufficient attention.
| Redundancy Approach | Mechanism | Suitable For |
|---|---|---|
| AWS RDS Multi-AZ | Synchronous standby; automatic failover | Cloud deployments on AWS |
| AWS Aurora PostgreSQL | Multi-primary compatible clustering | High-throughput cloud deployments |
| Cloud-provider equivalents | Varies by provider | Azure, GCP, OCI managed PostgreSQL |
| Self-managed replication with Patroni | PostgreSQL streaming replication; automated failover | On-premises and private cloud |
| Single containerized instance | None | Small teams, development and proof-of-concept |
Warning: Kasm ingests platform logs into the database by default. At scale with hundreds of concurrent sessions, this log volume can reach tens of gigabytes within days under default retention settings. For larger deployments, forwarding logs to an external SIEM and disabling Kasm's internal log retention both reduces storage requirements and removes I/O load that competes with operational queries. This is a critical configuration and a production readiness requirement at enterprise scale.
Docker Agents
Docker Agents are the compute nodes that provision and host containerized workspace sessions. Agent redundancy follows a straightforward principle: the more Agents in the zone, the smaller the impact of any single Agent failure.
When an Agent fails, sessions on that node are interrupted. Users reconnect, receiving a fresh container on a surviving Agent. Sessions on other Agents continue unaffected. New sessions are routed to healthy Agents automatically.
Warning: Autoscaling requires that the Upstream Auth Address zone setting be correctly configured before autoscaling is enabled. Newly provisioned Agent virtual machines must be able to reach the Web App API to register with the zone. If the Upstream Auth Address points to an internal IP or a single Web App server hostname rather than the load balancer, autoscaled Agents may fail to register silently. The virtual machine provider provisions the VM, but Kasm never sees a successful check-in, and capacity does not increase when needed. This is the most common autoscaling failure mode in enterprise deployments.
The Ephemeral Container Model
The ephemerality of containers is not a tradeoff: it is a feature of the security model that also simplifies the HA calculus.
In traditional VDI, a compromised persistent desktop remains compromised until discovered and remediated. The compromise may persist for days or weeks while an attacker maintains access. In a Kasm container session, the container is destroyed at session end, taking any compromise with it. The next session starts from a clean, verified image.
For HA purposes, the ephemerality of containers means there is no persistent data at risk when an Agent fails. A failed Agent takes nothing meaningful with it. The recovery operation is a session restart, not a virtual machine restoration procedure. The security benefit and the operational benefit are consequences of the same decision.
The Connection Proxy Tier: Gateway for Legacy Infrastructure
The Connection Proxy tier in RA3 provides web-native access to existing infrastructure: Windows servers, Linux systems, macOS machines, and any endpoint accessible via RDP, VNC, or SSH. It is an optional role; deployments that use only containerized workspaces are delivered through the Agent role.
A common enterprise pattern is hybrid delivery: containerized browser workspaces for secure web browsing alongside Connection Proxy-mediated RDP access for Windows line-of-business applications that require a full Windows environment.
RA3 as a Direct Expression of Zero Trust
RA3's architectural structure is not merely an engineering convenience. It is a direct expression of Zero Trust principles at the infrastructure level.
- The database sits in an isolated segment with no public interface. Only the Web App tier can reach it.
- The Docker Agents sit behind an internal Private Load Balancer with no public exposure. Users reach sessions through the proxy path, never directly to the container.
- The Connection Proxy tier translates legacy protocols into WebSocket before they reach the user's browser, eliminating the need to expose RDP, VNC, or SSH ports to the public internet.
- The Primary Load Balancer is the single controlled entry point where traffic inspection and WAF rules can be applied uniformly.
Each of these is an expression of the same principle: minimize the attack surface, enforce access through controlled choke points, and ensure that compromise in one component cannot be leveraged to attack another. The architecture does not trust that users connect from managed endpoints. It does not trust that the network outside the deployment boundary is clean. It trusts only the session token that the control plane issues, and it validates that token at every session connection.
This is what distinguishes RA3 from a collection of virtual machines running VDI software: it is an architecture designed around the assumption that trust must be earned at every boundary, not assumed at the perimeter.
This article is part of the Kasm Workspaces Reference Architecture Explanation Series.